
game engine
This game engine was developed for 2 main reasons, the first one was none of the game engines/frameworks on the market were that fast or were written in a horrible language like c++ or rust and wanting to create something myself. This was project was start after I finished my computer graphics course at uni. I wanted to explore more rendering techniques and just try to utilise all the knowledge I gathered from the course into a project.
If you want to skip to a specific part:
Language choice
This game engine was written in zig, why? Because:
-
C requires me to use some build system like cmake or just straight up makefiles. But c does allow me to do the meta programming shenanigans that I like.
-
Rust would require me to fight with the borrow checker the annoying rat, but does have a nice build system and great language features that would make it trivial to implement some of the features, but I felt like this project isn’t the type of thing that would benefit from rusts amazing error handling and memory safety
-
C++, I have only one word for why I wont use it “overloading”
-
Python, i have a lot of experience with this language but I believe it has little to no support for low level OpenGL calls, as well as being slow
-
Java, as much as I have come to respect java for the language that it, I still despise OOP with a passion even if it makes complete sense for OpenGL
-
Odin a very cool language for computer graphics with inbuilt quaternion types and matrixes, with amazing support for graphic libraries its just a little too new for me, having to compile it from scratch, but might be an idea to use in the future (but I still don’t like its use of the proc keyword for functions, a procedure is something completely different to a function)
So with why I did pick zig over basically every other language. Well the zig comptime keyword allows me to do the fun metaprogramming shenanigans that I love. As well as the zig having the best mascot (maybe except for V lang). zig also has some really cool features like allocators arnt global and you must pass them when every trying to add to the heap (great for embedded), it has oop in a sense but no inheritance (v tables arnt real and cant hurt me). As well as zig having quite honestly the best thing a very clean abstraction on SIMD instruction with the Vector type. Zig also has this amazing unit test system build into the language so you don’t have to have another dir called tests that just mirrors the main one, instead you can just write all your tests at the bottom of the file. All of these combined with a little personal bias made me picked zig.
Windowing and graphics libraries
Zig maybe be a really cool language with a great build system but it does currently lack something, a vast mature set of libraries (and documentation in some cases). This meant that only really low-level things were exposed, since zig integration with the c ABI allows for the large library projects like glfw, sdl, etc. to be ported easy. For this project I choose OpenGL as that is what my computer graphics course used and that being the one I had experience in, although I did also look at vulkan and decided not to due to the shear quantity of boiler plate and some of the strange dynamic linking with function pointers and wrappers that vulkan-zig uses. However in the future I would like to try vulkan again so I can abuse more threads in my program as well as try a openXR for VR applications. For this project I originally wanted to use SDL 2 for it being used within valves games as well as having the bare minimum of calls to implement things, so I could write my own subsystems. However when trying to get the opengl context to use with SDL2, it would not work no matter what I did, therefor I reverted back to GLFW, still has all the same features as SDL2 but sightly more bloat as I see it.
The math
So after starting rendering the obligatory triangle I realized that, I now need matrix/vector math to actually start to render 3D objects. Luckly I already had a file full of vector math from one of my previous projects writing a ray tracer in zig.
Vectors
This vector math was all done the normal way with struct that as 3 values, but zig has the inbuilt vector type that could easily be handle all these vector functions.
pub fn Vec(comptime length: comptime_int) type {
return struct {
const Self = @This();
vec: @Vector(length, f32),
}
Snippet of the vector type
This is a very thin abstraction the on the vector type that implements all your common operations, Add, sub, mul, div, norm, scale, etc. as well as a possibility to add 3 more for raytracing applications reflect, refract and a less common but really cool one reflectance for computing how things would bounce off water on a large scale. Comparing this new fancy vectorised one to the old slow vector struct running each test 200 times to get a clearer image of how long it took.
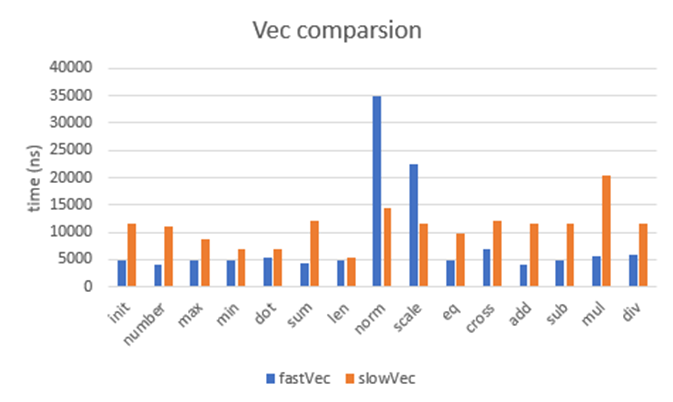 Graph of time comparison
Graph of time comparison
we can see all the functions are greatly faster other than the obvious ones. However min and dot were pretty similar. my guess for this is it got optimised down to near enough the same code. The len functions are the same but that’s to be expected. now on to the outlier’s norm and scale. These were computed on a vector length of 3, I believe this played a keyfactor within why they were slow.
pub fn mag(a: Self) f32 {
return @sqrt(@reduce(.Add, a.vec * a.vec));
}
pub fn norm(a: Self) Self {
return Self{ .vec = a.vec / number(a.mag()).vec };
}
pub fn scale(a: Self, b: f32) Self {
return Self{ .vec = a.vec * number(b).vec };
}
Vectorized norm and scale code
pub fn scale(a: Self, b: T) Self {
return Self{
.x = a.x * b,
.y = a.y * b,
.z = a.z * b,
};
}
// len here is mag
pub fn norm(a: Self) Self {
const den: T = len(a);
return a.scale(1 / den);
}
Non Vectorized code
as you can see in the vectorize code within norm, the first step that is done is to compute the magnitude of the vector, this as we saw in the graph took about the same time as the normal magnitude code, but then it is required to do another vector operation on top of that, as well needing to creating an entirely new vector from this number inorder to scale the rest, I believe this creation of the new vector is causing the largest slow down within this code. The scale function also suffers the same problem if I have to guess, creating a new vector within the code before doing the operation. However, this vector math code is still vastly faster than the original slow vector math, as well as being able to take full advantage of SIMD vectors, for when I want create vectors of arbitrary length
Matrix math
Now on to the good stuff, vector math is easy and only really has the basic operations to it, but matrix math has the good stuff in it, and the most potential for improvement. The matrix struct in the code much like the vector code, is a very thin wrapper on a vector. Although my matrix code differs from other peoples implementation as instead of using an array of vector for either each row or col I choose to use 1 long vector, this was done to make the addition of matrixes to each other simpler as well as giving rise to some interesting code.
pub const Mat3x3 = struct {
const Self = @This();
vec: @Vector(9, f32),
}
Snippet of the matrix type
The 3x3 matrix type implements most of the common operations, such as identity, mul and transpose. But as this is a game engine, we don’t care that much about the 3x3 matrix we care more about the 4x4 matrixes. These matrixes are implemented the same way but with a vector of 16 instead of 9. Now I will be explaining each function as my method of implementing them is unique and fully abuses the power of the abstraction of SIMD vectors.
Matrix multiplication
Lets start out with the bread and butter of a matrix math library, the most common operation and therefor the one that needs to be the fastest. Most implementation of this rely on the matrix already being separated in to rows/col for easy indexing for calculating the dot product like seen in the zig mach engine, but as my matrix only has one vector, this wasn’t going work. Therefor after some thinking my idea was to compute the all the multiplication and additions of the dot products in one go, this technique would allow the code to use larger SIMD vector like seen in SSE4 which my cpu supports (no I did not know this at the time). So the first step of the matrix mul is to compute the dot product of each row vector from matrix A and with each col vector from matrix B, if it is within the form of
Now if we look at the first item of C i.e. C0, 0
C[0,0]=A[0,0]B[0,0]+A[0,1]B[1,0]+A[0,2]B[0,2]+A[0,3]B[0,3]
And if we look at C1, 0: : C[1,0]=A[1,0]B[0,0]+A[1,1]B[1,0]+A[1,2]B[0,2]+A[1,3]B[0,3]
We can see that the elements of B do not change, so to calculate the first col of C we can copy B 4 times for each row of A which if we write it out in a slight nicer method, and by method I mean using a table:
| reg[0] | reg[1] | reg[2] | reg[3] | reg[4] | … |
|---|---|---|---|---|---|
| A[0, 0] | A[0, 1] | A[0, 2] | A[0, 3] | A[1, 0] | … |
| B[0, 0] | B[0, 1] | B[0, 2] | B[0, 3] | B[0, 0] | … |
| C[0,0]_0 | C[0,0]_1 | C[0,0]_2 | C[0,0]_3 | C[1,0]_0 | … |
And the dot product of the C at the index [i, j] being the:
Or rewriting it in the form as before: C[0,0]=A[0,0]B[0,0]+A[0,1]B[1,0]+A[0,2]B[0,2]+A[0,3]B[0,3] = C[0,0]0 + C[0,0]1 + C[0,0]2 + C[0,0]3
For sake of space I wont write out the full thing since its 64 items longs but you get the drift, just you can expand out all the multiplication of all the dot products within the matrix mul, and this is how you get the 2 large 64 long masks as you can see in the mat mul function [here].
now that we have done all the multiplications we now actually need to do the summing of all these dot products. A sane person may extract them out then reduce them in their own vectors, however I am not sane, and since we already have them in the vector format we may as well keep them there. Therefor the dot product is done in vaguely the same way as the mul step, all at once or as close as we can. So this time we align all C\left[i,j\right]_w indexes to each other so in 4 different vectors C[0, 0]0 , C[0, 0]1 , C[0, 0]2 , C[0, 0]3 will all be at index 0 in all 4 vectors, looking at this using the same table method as before:
| … | ||
|---|---|---|
| C[0,0]_0 | C[1,0]_0 | … |
| C[0,0]_1 | C[1,0]_1 | … |
| C[0,0]_2 | C[1,0]_2 | … |
| C[0,0]_3 | C[1,0]_3 | … |
then you just add all 4 of these vectors together and get all the dot products of all the values in the right indexes.
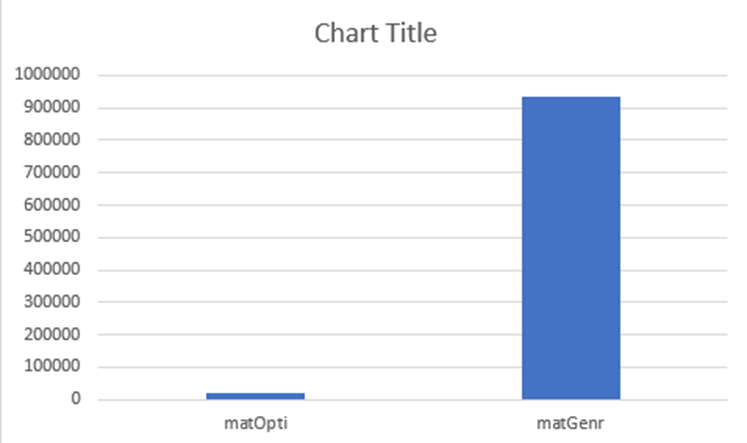
Now this idea does sound slightly on the insane side, but comparing it with a conventional matrix mul as can be seen below we can see that this is ~50x faster than the normal matrix mul. However I believe the vast majority of this speed up is from the fact my CPU has [sse4] which will allow for the full computation of the 64 mul step to be done at once rather than break it up like cpus that don’t have the full sse instructing set will do.
I am still writing more of this